BIG DATA & DATA ANALYSIS
Tesla Motors, Inc. is an American automotive and energy storage company that designs, manufactures, and sells electric cars, electric vehicle powertrain components, and battery products. Tesla Motors is a public company that trades on the NASDAQ stock exchange under the symbol TSLA. During the first quarter of 2013, Tesla posted profits for the first time in its history.
PROBLEM
- Tesla is obviously aiming beyond the vehicle cockpit. Tesla is aiming to become the Innovation of the auto industry. It’s not the hardware or software that makes the sale. It’s the integration and intelligence between the hardware and software.
- The car provide approx. 2-5TB’s data incoming every week (vital indicators, how the cars are used, etc)
- Many indicators are taken, will be stored as data
- The catch is that Tesla is going to be overloaded with data.
- Tesla has been an early pioneer in collecting and processing big data and using it in ways to enhance its business. But now, it wants to use big data in the same ways that companies like Google, Amazon, and Facebook use it — to streamline and customize the user experience.
TESLA LINE-UP



BIG DATA SOLUTION
- Tesla produces high tech and technologically advanced electric cars. Many cutting edge technologies are implemented inside the car, even an autopilot is installed in the car. Of course, Tesla is the poster child for instrumenting vehicles with sensors and sending all the data back to the mother ship for analysis, using an Apache Hadoop® cluster to collect the data.
- The data is used to improve the company’s R&D, car performance, car maintenance, and customer satisfaction, and also future products development and improvement.
- The electric carmaker, which produces the most connected car in the market – the Tesla S, currently collects data from its cars purely for research and development for car maintenance. This allows IT, engineers and the manufacturing lines to resolve issues and send back fixes with its over-the-air software updates.
- But as its big data increases, it will use the cluster to learn more about its customers, influencing business decisions.
- “We are working on a big data platform…The car is connected, but it does not really talk to the network every minute because we want to keep it as smart and efficient as possible.”
- For instance, the company is notified if the car is not functioning properly and consumers can be advised to get a service, and actions can be taken properly. These capabilities have helped Tesla create market share in a difficult environment where charging stations are not widely deployed.
OTHER BIG DATA & DATA ANALYTICS TOOLS USED
- SAS Eminer: Descriptive and predictive modeling provide insights that drive better decision making.
- Tableau: For data visualization.
- SPASS: With SPSS predictive analytics software, you can predict with confidence what will happen next so that you can make smarter decisions, solve problems and improve outcomes.
- R: Recently tesla motors have started working on R packages (YES! They’re also using R just like us in the Laboratory Session:) )
- Python: Python is also adapted for analytic’s.
- Zoho Reports: For online reporting.
- NodeXL: NodeXL is a powerful and easy-to-use interactive network visualisation and analysis tool that leverages the widely available MS Excel application as the platform for representing generic graph data, performing advanced network analysis and visual exploration of networks
- Excel: Still used in Tesla Motors.
- SQL: Some Data scientist works on SQL in Tesla motors
METHODOLOGY & MODEL
This case will use Data Mining Methodology, especially CLASSIFICATION and CLUSTERING.
Data Mining : Generally, data mining (sometimes called data or knowledge discovery) is the process of analyzing data from different perspectives and summarizing it into useful information – information that can be used to increase revenue, cuts costs, or both. Data mining software is one of a number of analytical tools for analyzing data. It allows users to analyze data from many different dimensions or angles, categorize it, and summarize the relationships identified. Technically, data mining is the process of finding correlations or patterns among dozens of fields in large relational databases.
Analysis :
Classification : It is classified as Classification because the data that are taken from the vehicles are used to determine the expected period of some system. For instance, the system will calculate when is the right time to do Service, change oil, etc. Or they can use it to give recommendations about their customer problems. It also can be used to improve customer satisfaction.
Clustering : It is classified as Clustering because it is used to analyse data sets without label, such as the data that are taken from the vehicles, mostly come in “values”.
Classification
| Engine Status | Car Age | Oil Temp | ECU Status | Engine Temp | Electrical Status | Recommendation |
| OK | 1-5 | 85-90°C | OK | 84-102°C | OK | OK |
| ERROR | 5-10 | >95°C | FAULT | >102°C | FAULT | FAULT. INSPECTION. |
CLUSTERING
| ENGINE |
| E1 | E2 | E3 | E4 | E5 | E6 | E7 |
| 1.02 | 4.02 | 102 | 84 | 112 | 18 | 101 |
MEASUREMENT :
To get the actual live measurement of the cars, Tesla uses its on board computer (OBU) to read the data and send it directly to Tesla. Big data’s will be collected from the cars, mainly the vital indicators such as engines, electrical, mechanical, etc. Tesla will develop the raw data into meaningful information for the customer. The data sets, values, raw data, parameters, will be analysed properly in order to inform the driver. Most of the information are intended to increase the Service for the customer, which will also increase the customer satisfaction.Unlike any other car company, Tesla fully instruments its cars by default, connecting them wirelessly to their corporate offices for analysis.
ACCURACY :
In order to get high accuracy, i think that we should implement 8 ways of improving data accuracy:
1. Add more data
Having more data is always a good idea. It allows the “data to tell for itself,” instead of relying on assumptions and weak correlations. Presence of more data results in better and accurate models.
I understand, we don’t get an option to add more data. For example: we do not get a choice to increase the size of training data in data science competitions. But while working on a company project, I suggest you to ask for more data, if possible. This will reduce your pain of working on limited data sets.
2. Treat missing and Outlier values
The unwanted presence of missing and outlier values in the training data often reduces the accuracy of a model or leads to a biased model. It leads to inaccurate predictions. This is because we don’t analyse the behavior and relationship with other variables correctly. So, it is important to treat missing and outlier values well.
- Missing: In case of continuous variables, you can impute the missing values with mean, median, mode. For categorical variables, you can treat variables as a separate class. You can also build a model to predict the missing values. KNN imputation offers a great option to deal with missing values.
- Outlier: You can delete the observations, perform transformation, binning, Imputation (Same as missing values) or you can also treat outlier values separately. You can refer article
3. Feature Engineering
This step helps to extract more information from existing data. New information is extracted in terms of new features. These features may have a higher ability to explain the variance in the training data. Thus, giving improved model accuracy.
Feature engineering is highly influenced by hypotheses generation. Good hypothesis result in good features. That’s why, I always suggest to invest quality time in hypothesis generation. Feature engineering process can be divided into two steps:
- Feature transformation: There are various scenarios where feature transformation is required:
A) Changing the scale of a variable from original scale to scale between zero and one. This is known as data normalization. For example: If a data set has 1st variable in meter, 2nd in centi-meter and 3rd in kilo-meter, in such case, before applying any algorithm, we must normalize these variable in same scale.
B) Some algorithms works well with normally distributed data. Therefore, we must remove skewness of variable(s). There are methods like log, square root or inverse of the values to remove skewness.
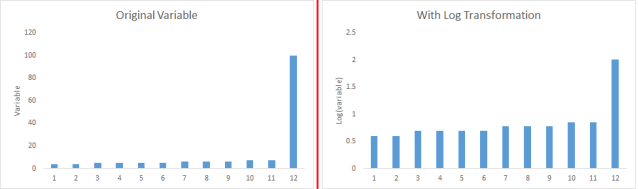 C) Some times, creating bins of numeric data works well, since it handles the outlier values also. Numeric data can be made discrete by grouping values into bins. This is known as data discretization.
C) Some times, creating bins of numeric data works well, since it handles the outlier values also. Numeric data can be made discrete by grouping values into bins. This is known as data discretization.
- Feature Creation: Deriving new variable(s ) from existing variables is known as feature creation. It helps to unleash the hidden relationship of a data set. Let’s say, we want to predict the number of transactions in a store based on transaction dates. Here transaction dates may not have direct correlation with number of transaction, but if we look at the day of a week, it may have a higher correlation. In this case, the information about day of a week is hidden. We need to extract it to make the model better.
4. Feature Selection
Feature Selection is a process of finding out the best subset of attributes which better explains the relationship of independent variables with target variable.
You can select the useful features based on various metrics like:
- Domain Knowledge: Based on domain experience, we select feature(s) which may have higher impact on target variable.
- Visualization: As the name suggests, it helps to visualize the relationship between variables, which makes your variable selection process easier.
- Statistical Parameters: We also consider the p-values, information values and other statistical metrics to select right features.
- PCA: It helps to represent training data into lower dimensional spaces, but still characterize the inherent relationships in the data. It is a type of dimensionality reduction technique. There are various methods to reduce the dimensions (features) of training data like factor analysis, low variance, higher correlation, backward/ forward feature selection and others.
- PCA: It helps to represent training data into lower dimensional spaces, but still characterize the inherent relationships in the data. It is a type of dimensionality reduction technique. There are various methods to reduce the dimensions (features) of training data like factor analysis, low variance, higher correlation, backward/ forward feature selection and others.
5. Multiple algorithms
Hitting at the right machine learning algorithm is the ideal approach to achieve higher accuracy. But, it is easier said than done.
This intuition comes with experience and incessant practice. Some algorithms are better suited to a particular type of data sets than others. Hence, we should apply all relevant models and check the performance.
6. Algorithm Tuning
We know that machine learning algorithms are driven by parameters. These parameters majorly influence the outcome of learning process.
The objective of parameter tuning is to find the optimum value for each parameter to improve the accuracy of the model. To tune these parameters, you must have a good understanding of these meaning and their individual impact on model. You can repeat this process with a number of well performing models.
For example: In random forest, we have various parameters like max_features, number_trees, random_state, oob_score and others. Intuitive optimization of these parameter values will result in better and more accurate models.
EVALUATION :
In making Tesla as high technology company that produces cars, using it’s big data sources and system has been an important and very vital, if only Tesla uses big data, Tesla will be able to provide better consumer services to its customer, which will satisfy their customer. Tesla has implemented a lot of big data tools to help Tesla in improving their Business. Each tools sometimes has specific function to big data, and it works in synergy
Tesla’s customer care exceeds what every other car company provides, which more than overcomes the near-impossibility of living off a single car design and an electric platform that lags far behind the gas-based system currently in place. Tesla is the best example of what applied analytics can do with respect to competitiveness. Without it, Tesla likely would have failed.
“The Tesla isn’t a perfect car, especially in a market still dominated by gas guzzlers. But the company’s widespread use of analytics to study its vehicles improves the customer experience and offers a lesson to automobile industry mainstays still resting on their laurels.”
Ref :
http://www.cio.com/article/2462414/big-data/why-analytics-makes-tesla-better-than-jaguar.html

{kind=link}